The first beta version of Mr. DLib V2 has been released and is performing very well so far. With our partner JabRef, we have delivered over 70 thousand sets of recommendations (approximately 1000 per day), or a total of over 450,000 individual recommendations. We have a click through rate (CTR) on these recommendations of approximately 0.7% which corresponds to a recommendation being clicked on about 1 in every 25 sets being delivered. This CTR as it is a significant improvement on Mr. DLib V1, which had a CTR of approximately 0.2%. Our recommendations are being delivered in an average of 3.5 seconds, which is quicker than the old system, and we hope to improve further on the speed of recommendation delivery. Instead of previously about 10 million documents from the CORE corpus, Mr. DLib has now indexed more than 100 million documents from CORE.
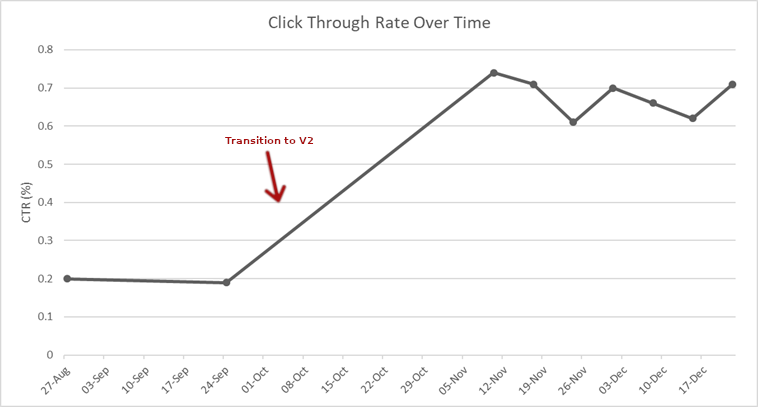
Change in CTR over transition from V1 to V2
We are now starting development on the meta-learning engine which will allow the system to adapt its recommendation approach for each request according to the context. We hope this will lead to recommendations being more useful and more varied. We are looking to integrate the system into many more platforms in the coming months.
The Mr. DLib V2 web service is implemented using Python Flask and content based filtering is provided by Apache Solr as in V1. Responses from Mr. DLib V2 are delivered in JSON instead of XML, but still use the same endpoints as Mr. DLib V1. Check out the example below to try out the new system: